Ubuntuでソフトのインストーラーが実行できない時の対処方(VOICEPEAKのインストールができない)
コミュニケーションロボットの声に音声合成ソフトの「VOICEPEAK」を採用したが、 Linux用の最新版セットアップファイルのダウンローダーが実行できない問題に直面した。
・今回起動させたいファイル
voicepeak-downloader-linux64
解決方法
sudo chmod 777 <ファイル名>
chmodで実行権限を与えてみたところ、動いてくれました。
./<ファイル名>で起動するはずです。
その後、インストーラーがzipファイルで生成されます。
そのzipファイルを解凍して、その中のvoicepeakを再びchmodで実行権限を与え、実行させます。
この方法で無事動きました!!
ROSでDynamixelを動かす方法1
この記事は、ROS1及び通信プロトコル2.0のDynamixel xシリーズを使用しています。
環境
Ubuntu20.04
ROS Noetic
ROSのインストール
公式のインストール手順
noetic/Installation/Ubuntu - ROS Wiki
- sources.list をセットアップする
sudo sh -c 'echo "deb http://packages.ros.org/ros/ubuntu $(lsb_release -sc) main" > /etc/apt/sources.list.d/ros-latest.list'
- キーの設定
sudo apt-key adv --keyserver 'hkp://keyserver.ubuntu.com:80' --recv-key C1CF6E31E6BADE8868B172B4F42ED6FBAB17C654
- パッケージを更新
sudo apt update
- インストール
sudo apt install ros-noetic-desktop-full
- 環境設定
echo "source /opt/ros/noetic/setup.bash" >> ~/.bashrc
source ~/.bashrc
- パッケージを構築するための依存関係
sudo apt install python3-rosdep python3-rosinstall python3-rosinstall-generator python3-wstool build-essential
- rosdepの初期化
sudo rosdep init
rosdep update
- catkin buildを使えるようにする
sudo apt install python3-osrf-pycommon python3-catkin-tools
sudo apt install build-essential
- ROSワークスペースの作成
mkdir -p ~/catkin_ws/src
cd ~/catkin_ws/
catkin build
echo "source ~/catkin_ws/devel/setup.bash" >> ~/.bashrc
source ~/.bashrc
Dynamixelの環境構築
公式の環境構築手順
- ライブラリのダウンロード
cd ~/catkin_ws/src
git clone https://github.com/ROBOTIS-GIT/dynamixel-workbench.git
git clone https://github.com/ROBOTIS-GIT/dynamixel-workbench-msgs.git
git clone https://github.com/ROBOTIS-GIT/DynamixelSDK.git
catkin build
- rulesファイルのコピー
cd ~/
wget https://raw.githubusercontent.com/ROBOTIS-GIT/dynamixel-workbench/master/99-dynamixel-workbench-cdc.rules
sudo cp ./99-dynamixel-workbench-cdc.rules /etc/udev/rules.d/
sudo udevadm control --reload-rules
sudo udevadm trigger
Dynamixelのパッケージの作成
今回は、チュートリアルのパッケージを作ります。
- パッケージの作成
cd ~/catkin_ws/src
catkin_create_pkg dynamixel_tutorial rospy
mkdir -p dynamixel_tutorial/{config,launch}
cp dynamixel-workbench/dynamixel_workbench_controllers/launch/dynamixel_controllers.launch dynamixel_tutorial/launch/
cp dynamixel-workbench/dynamixel_workbench_controllers/config/joint_2_0.yaml dynamixel_tutorial/config/
- dynamixel_tutorialに複製したconfigファイルをlaunchで読み込めるようにするため、dynamixel_controllers.launchを編集
cd ~/catkin_ws/src/dynamixel_tutorial/launch
vim dynamixel_controllers.launch
10行目のvalueを下記に変更
<param name="dynamixel_info" value="$(find dynamixel_tutorial)/config/joint_2_0.yaml"/>
vimを終了させて、ビルド
catkin build
モータの配線と各種設定
下の記事に詳しく記載されているので、この記事では省略します。
主にやることは次の通りです。
配線
DYNAMIXEL Wizard 2.0のインストール
DYNAMIXEL Wizard 2.0でID番号を設定する
今回は、Dynamixel xシリーズのモータを2個使用します。
接続確認
sudo chmod 666 /dev/ttyUSB0
roscore
rosrun dynamixel_workbench_controllers find_dynamixel /dev/ttyUSB0
id : 1とid : 2のモータが出力されたことを確認する。
Topic通信で動かす
この例では、以下のように動作させます。
ID:1のモータを1.0秒かけて30°に回転
ID:1とID:2のモータを1.0秒かけて-30°に回転
ID:1とID:2のモータを1.5秒かけて0°に回転
Pythonファイルの作成
cd ~/catkin_ws/src/dynamixel_tutorial/src
vim by_topic.py
以下のコードを張り付ける
#!/usr/bin/env python
# -*- coding: utf-8 -*
import math
import rospy
from trajectory_msgs.msg import JointTrajectory, JointTrajectoryPoint
def degToRad(deg):
return math.radians(deg)
def motorPub(joint_name, joint_angle, execute_time=1.0):
# Publisherの定義
motor_pub = rospy.Publisher('/dynamixel_workbench/joint_trajectory',JointTrajectory,queue_size=10)
rospy.sleep(0.5)
# publishするデータの定義
msg = JointTrajectory()
msg.header.stamp = rospy.Time.now()
msg.joint_names = joint_name
msg.points = [JointTrajectoryPoint()]
msg.points[0].positions = list(map(degToRad, joint_angle))
msg.points[0].time_from_start = rospy.Time(execute_time)
# publish
motor_pub.publish(msg)
if __name__ == '__main__':
rospy.init_node('dynamixel_by_topic')
motorPub(['pan'], [30])
rospy.sleep(2.0)
motorPub(['pan', 'tilt'], [-30, -30])
rospy.sleep(2.0)
motorPub(['pan', 'tilt'], [0, 0], 1.5)
pythonファイルに権限を付与させる
chmod 755 by_topic.py
- 実行させる
roslaunch dynamixel_tutorial dynamixel_controllers.launch
rosrun dynamixel_tutorial by_topic.py
Service通信で動かす
- Pythonファイルの作成
cd ~/catkin_ws/src/dynamixel_tutorial/src
vim by_service.py
以下のコードを張り付ける
# Service制御
def degToStep(deg):
return int((deg+180)/360.0*4095)
def setPosition(motor_id, position):
# Service Clientの定義
motor_client = rospy.ServiceProxy('/dynamixel_workbench/dynamixel_command',DynamixelCommand)
# degreesを4096段階のstep(12bit)に変換
step = degToStep(position)
# 許容電圧を指定
motor_client('', motor_id, 'Goal_Current', 200)
# 目標角度を指定
motor_client('', motor_id, 'Goal_Position', step)
if __name__ == '__main__':
rospy.init_node('dynamixel_by_service')
setPosition(0, 30)
rospy.sleep(2.0)
setPosition(1, 30)
rospy.sleep(2.0)
setPosition(0, 0)
setPosition(1, 0)
pythonファイルに権限を付与させる
chmod 755 by_topic.py
- 実行させる
roslaunch dynamixel_tutorial dynamixel_controllers.launch
rosrun dynamixel_tutorial by_service.py
Pythonを使ってAIとおしゃべりがしたい
AIの友達が欲しい。
AIとおしゃべりがしたい。
去年からそんなことを思いつつ、色々試していました。
そして最近、便利なツールがたくさん出てきたおかげで、AIとおしゃべりできるシステムが簡単に作れるようになりました。
そこで、私なりに作ってみた(組み合わせただけ)会話システムをまとめました。
この記事でできること
AIとおしゃべり(雑談)するシステムをPythonで作ることができます。
具体的には、マイク入力、音声認識、雑談生成、感情認識、音声合成です。
使ったもの
・whisper(音声認識)
・mebo(雑談)
・Cotoha API(感情認識)
・VOICEVOX(音声合成)
目次
今まで作ったもの
初めて会話システムを作ったときに利用したのが、名古屋工業大学が開発したMMDAgentです。
MMDAgentは、決められた通りの受け答えしかできません。
そして、だいぶ前に開発されたものなので、外部との連携ができませんでした。
そのため、友達1号の開発は終了しました。
 続いて、ドコモAIエージェントサービスを使用して、AIと会話するシステムを作りました。
続いて、ドコモAIエージェントサービスを使用して、AIと会話するシステムを作りました。
システムの構成は下の図の通りです。
 GUIには、Unityを使用しており、音声認識や音声合成、シナリオ作成にはドコモAIエージェントサービスを使用しています。そして、雑談や天気予報などは外部のAPIを使用していました。
GUIには、Unityを使用しており、音声認識や音声合成、シナリオ作成にはドコモAIエージェントサービスを使用しています。そして、雑談や天気予報などは外部のAPIを使用していました。
しかし、雑談をするために会話型AI構築サービスのmeboをドコモAIエージェントと連携させようとしましたが、できませんでした。
そのため雑談には、chaplus 対話API βを使用していたが、それも最近サービスが終了してしまいました。
そして、友達2号の開発は終了しました。
今回作ったもの
ドコモAIエージェントサービスもいつまで使えるか分からないので、ドコモAIエージェントサービスの部分をPythonで作りました。
開発環境
・Ubuntu20.04
・Intel core i7 7700hq
・GeForce GTX1050
構成
全体の流れは、以下の通りです。
ユーザーの発話
↓
whisper(音声認識)
↓
mebo(返事を生成)
↓
Cotoha API(返事の感情を認識)
↓
VOICEVOX(音声合成)
↓
ユーザー
whisper
whisperは、OpenAIが公開したオープンソースの素晴らしい音声認識モデルです。
これを使用することにより、ローカル環境で高精度な音声認識を行えます。
mebo
meboは、GPTベースの会話型AI構築サービスです。
キャラクターも設定できて面白いです。
Cotoha API
NTTグループの40年以上の研究成果を活かした自然言語処理技術や音声認識・合成技術を、APIでお手軽に利用できるよう提供しているサービスです。
VOICEVOX
無料で使える中品質なテキスト読み上げソフトウェアです。
インストール
音声認識
whisperをインストール
以下のコマンドでwhisperをインストールする。
pip install git+https://github.com/openai/whisper.git
依存関係のffmpegをインストールする。
(無くても動く場合もある)
pip install ffmpeg-python
Speech Recognitionをインストール
pip install SpeechRecognition
依存関係のPyAudioをインストールする。
sudo apt install python3-pyaudio
その他必要なものをインストール
SoundFile
pip install soundfile
numpy
pip install numpy
返事を生成、返事の感情を認識
mebo、Cotoha APIとのやり取りには、Pythonで使われるHTTPライブラリであるrequestsを使用しました。
pip install requests
VOICEVOXをインストール
VOICEVOXは、以下のサイトを参考にしてインストールしてください。
GPU環境がない人は、CPU版をインストールしてください。
VOICEVOXで生成された音声ファイルを再生するためにplaysoundを使用しました。
pip install playsound
APIの準備
mebo
下のサイトからmeboを作って下さい。
meboの詳しい使い方は、下の記事を見てください。
meboでAPIを共有する方法は、下の記事を見てください。
作成したエージェントとAPI経由で会話する|mebo(ミーボ)ではじめる会話AI構築
必要なもの
・エンドポイント
・APIキー
・エージェントID
・ユーザの発話
・ユーザ識別子
エンドポイント(共通)
https://api-mebo.dev/api
APIキー、エージェントIDは、以下の場所から入手できます。

ユーザ識別子(uid)を含めると、ユーザごとにステートを保持することができるので、必要な人は任意のユーザー識別子を設定してください。
Cotoha API
下のサイトからCotoha APIのアカウントを作って下さい。
api.ce-cotoha.com
詳しい使い方は公式リファレンスを見てください。
必要なもの
・client_id
・client_secret
・Access Token Publish URL
Access Token Publish URL (共通)
https://api.ce-cotoha.com/v1/oauth/accesstokens
ソースコード(GPU)
###################################
# AIトークシステム
# VOICEVOXを起動させてから実行する
###################################
from io import BytesIO
import numpy as np
import soundfile as sf
import speech_recognition as sr
import whisper
import requests
import json
import wave
from pprint import pp
from playsound import playsound
# whisperでマイクから文字起こし
def transcription(model,recognizer):
with sr.Microphone(sample_rate=16_000) as source:
print("なにか話してください")
audio = recognizer.listen(source)
print("音声処理中 ...")
wav_bytes = audio.get_wav_data()
wav_stream = BytesIO(wav_bytes)
audio_array, sampling_rate = sf.read(wav_stream)
audio_fp32 = audio_array.astype(np.float32)
result = model.transcribe(audio_fp32, fp16=False,language="ja")
print(result["text"])
return result
# VOICEVOXで音声合成
def generate_wav(text, speaker=8, filepath='./audio.wav'):
host = 'localhost'
port = 50021
params = (
('text', text),
('speaker', speaker),
)
response1 = requests.post(
f'http://{host}:{port}/audio_query',
params=params
)
headers = {'Content-Type': 'application/json',}
response2 = requests.post(
f'http://{host}:{port}/synthesis',
headers=headers,
params=params,
data=json.dumps(response1.json())
)
wf = wave.open(filepath, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(24000)
wf.writeframes(response2.content)
wf.close()
# meboAPIの使用
def mebo(text):
url = "https://api-mebo.dev/api"
headers = {'content-type': 'application/json'}
item_data = {
"api_key": "APIキー",
"agent_id": "エージェントID",
"utterance": text,
"uid": "ユーザ識別子"
}
r = requests.post(url,json=item_data,headers=headers)
print(r)
print(r.json()["bestResponse"]["utterance"])
return r
# cotohaAPIの使用
def cotoha(sentence):
client_id = 'Client ID って書いてあるところにあるやつ'
client_secret = 'Client Secret って書いてあるところにあるやつ'
url = 'Access Token Publish URL って書いてあるところにあるやつ'
headers = {
'Content-Type': 'application/json'
}
data = json.dumps({
'grantType' : 'client_credentials',
'clientId' : client_id,
'clientSecret': client_secret
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
access_token = response['access_token']
# 解析モード選択(今回は感情認識)
url = 'https://api.ce-cotoha.com/api/dev/nlp/v1/sentiment'
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'Authorization': f'Bearer {access_token}'
}
data = json.dumps({
'sentence': sentence
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
# 辞書を見やすく整形して出力
pp(response)
# return response
if __name__ == "__main__":
# wisperの設定
model = whisper.load_model("base",device="cpu")
_ = model.half()
_ = model.cuda()
for m in model.modules():
if isinstance(m, whisper.model.LayerNorm):
m.float()
recognizer = sr.Recognizer()
while True:
# whisperマイクから文字起こし
result = transcription(model,recognizer)
# mebo雑談
r = mebo(result["text"])
# cotoha感情認識
cotoha(r.json()["bestResponse"]["utterance"])
# 音声合成
generate_wav(r.json()["bestResponse"]["utterance"])
# 音声再生
playsound("audio.wav")
実行させる前に、VOICEVOX(GUI)を起動させておく。
ソースコード(CPU)
###################################
# AIトークシステム
# VOICEVOXを起動させてから実行する
###################################
from io import BytesIO
import numpy as np
import soundfile as sf
import speech_recognition as sr
import whisper
import requests
import json
import wave
from pprint import pp
from playsound import playsound
# whisperでマイクから文字起こし
def transcription(model,recognizer):
with sr.Microphone(sample_rate=16_000) as source:
print("なにか話してください")
audio = recognizer.listen(source)
print("音声処理中 ...")
wav_bytes = audio.get_wav_data()
wav_stream = BytesIO(wav_bytes)
audio_array, sampling_rate = sf.read(wav_stream)
audio_fp32 = audio_array.astype(np.float32)
result = model.transcribe(audio_fp32, fp16=False,language="ja")
print(result["text"])
return result
# VOICEVOXで音声合成
def generate_wav(text, speaker=8, filepath='./audio.wav'):
host = 'localhost'
port = 50021
params = (
('text', text),
('speaker', speaker),
)
response1 = requests.post(
f'http://{host}:{port}/audio_query',
params=params
)
headers = {'Content-Type': 'application/json',}
response2 = requests.post(
f'http://{host}:{port}/synthesis',
headers=headers,
params=params,
data=json.dumps(response1.json())
)
wf = wave.open(filepath, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(24000)
wf.writeframes(response2.content)
wf.close()
# meboAPIの使用
def mebo(text):
url = "https://api-mebo.dev/api"
headers = {'content-type': 'application/json'}
item_data = {
"api_key": "APIキー",
"agent_id": "エージェントID",
"utterance": text,
"uid": "ユーザ識別子"
}
r = requests.post(url,json=item_data,headers=headers)
print(r)
print(r.json()["bestResponse"]["utterance"])
return r
# cotohaAPIの使用
def cotoha(sentence):
client_id = 'Client ID って書いてあるところにあるやつ'
client_secret = 'Client Secret って書いてあるところにあるやつ'
url = 'Access Token Publish URL って書いてあるところにあるやつ'
headers = {
'Content-Type': 'application/json'
}
data = json.dumps({
'grantType' : 'client_credentials',
'clientId' : client_id,
'clientSecret': client_secret
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
access_token = response['access_token']
# 解析モード選択(今回は感情認識)
url = 'https://api.ce-cotoha.com/api/dev/nlp/v1/sentiment'
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'Authorization': f'Bearer {access_token}'
}
data = json.dumps({
'sentence': sentence
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
# 辞書を見やすく整形して出力
pp(response)
# return response
if __name__ == "__main__":
# wisperの設定
model = whisper.load_model("base",device="cpu")
recognizer = sr.Recognizer()
while True:
# whisperマイクから文字起こし
result = transcription(model,recognizer)
# mebo雑談
r = mebo(result["text"])
# cotoha感情認識
cotoha(r.json()["bestResponse"]["utterance"])
# 音声合成
generate_wav(r.json()["bestResponse"]["utterance"])
# 音声再生
playsound("audio.wav")
実行させる前に、VOICEVOX(GUI)を起動させておく。
実行結果
結果は下の図のようになります。

「こんにちは」と話しかけると、「こんにちは!」と返してくれました。
また、resultに感情の結果も出力されています。今回は、sentimentがNeutralで、そのスコアが、0.4826886679492818となりました。
この感情表現の結果をもとに、キャラクターの表情やしゃべり方を変えると、いい感じに会話できると思います。
ソースコードの説明
whisperでマイクから文字起こし
以前に書いた記事を見てください。
whisperのモデルは5種類用意されています。
ここではbaseを使用しています。
感激!✨こんなに少ないコードで音声を文字に変換できるなんて😭✨感激し過ぎたせいで全モデル試してしもた!! pic.twitter.com/WPY337P1Qx
— みやさかしんや@Python/DX/エンジニア (@miyashin_prg) February 10, 2023
mebodで雑談の返答を生成
以前に書いた記事を見てください。
Cotoha APIで感情認識
下の記事を参考にしました。
VOICEVOXで音声合成
下の記事を参考にしました。
def generate_wav(text, speaker=8, filepath='./audio.wav'):のspeaker=の数字を変えることで、読んでくれるキャラクターが変わります。
話者ID一覧
0 四国めたん あまあま
1 ずんだもん あまあま
2 四国めたん 四国めたん
3 ずんだもん ずんだもん
4 四国めたん セクシー
5 ずんだもん セクシー
6 四国めたん ツンツン
7 ずんだもん ツンツン
8 春日部つむぎ 春日部つむぎ
9 波音リツ 波音リツ
10 雨晴はう 雨晴はう
11 玄野武宏 玄野武宏
12 白上虎太郎 ふつう
13 青山龍星 青山龍星
14 冥鳴ひまり 冥鳴ひまり
15 九州そら あまあま
16 九州そら 九州そら
17 九州そら セクシー
18 九州そら ツンツン
19 九州そら ささやき
20 もち子さん もち子さん
21 剣崎雌雄 剣崎雌雄
22 ずんだもん ささやき
23 WhiteCUL WhiteCUL
24 WhiteCUL たのしい
25 WhiteCUL かなしい
26 WhiteCUL びえーん
27 後鬼 人間ver.
28 後鬼 ぬいぐるみver.
29 No.7 No.7
30 No.7 アナウンス
31 No.7 読み聞かせ
32 白上虎太郎 わーい
33 白上虎太郎 びくびく
34 白上虎太郎 おこ
35 白上虎太郎 びえーん
36 四国めたん ささやき
37 四国めたん ヒソヒソ
38 ずんだもん ヒソヒソ
whiperの高速化(ちょっとだけ)
下の記事を参考にしましました。
今回は記事に書いてある、重みのfp16化を行いました。
Whisper自体の変更は無く、呼び出し方を変え、重みも fp16 で演算することによって若干の高速化と省メモリ化を行います。
import whisper
model = whisper.load_model("base", device="cpu")
_ = model.half()
_ = model.cuda()
# exception without following code
# reason : model.py -> line 31 -> super().forward(x.float()).type(x.dtype)
for m in model.modules():
if isinstance(m, whisper.model.LayerNorm):
m.float()
今後の課題
今後は、GUIを作って、キャラクターにしゃべってもらいたいです。
また、雑談の返答と感情認識以外はローカルで動かいているので、その2つもローカルで動くようにさせたいです。
参考サイト
・whisperを使ってマイクから文字起こしをする部分
声をPythonに聴かせて(マイクから入力した声をWhisperに、何度でも認識させよう) - nikkie-ftnextの日記
・mebo公式リファレンス
mebo(ミーボ)ではじめる会話AI構築
・PythonとAPIのやり取りをしている部分
Python, RequestsでWeb APIを呼び出し(データ取得・操作) | note.nkmk.me
・Cotoha API公式リファレンス
APIリファレンス | COTOHA API
・Cotoha APIとPythonの連携
Cotoha API を使ってみた | Withcation
・VOICEVOXとPythonの連携
PythonからVOICEVOXを使う - Qiita
VOICEVOXエンジンを使ったPythonでの「高」品質音声合成API | 鷹の目週末プログラマー
・whisperの高速化の部分
音声認識モデル Whisper の推論をほぼ倍速に高速化した話 - Qiita
Pythonとwhisperを使ってマイク入力による文字起こしをする(CPU)
whisperは、OpenAIが公開したオープンソースの素晴らしい音声認識モデルです。
これを使用することにより、ローカル環境で高精度な音声認識を行えます。
今回は、マイク入力でム文字起こしをしてみました。
この記事を参考にして動かしました。
詳しいことはこの記事を見てください。
nikkie-ftnext.hatenablog.com
仕組み
マイク入力
↓
「Speech Recognition」で音声データ作成
↓
「SoundFile」で音声データの読み込み
↓
「whisper」で文字起こし
マイク入力には、「Speech Recognition」と呼ばれるPythonのライブラリを使用する。
「Speech Recognition」を使用すると、音の波形が小さくなったところで音声ファイルを切ってくれる。
また、「Speech Recognition」の依存関係である「PyAudio」が2022年12月26日に新しいバージョン(0.2.13)を出したためPython3.8以上でも使えるようになりました。(やったー)
続いて「SoundFile」で音声データの読み込み、「whisper」で文字起こしを行う。
環境
・Ubuntu20.04
・Python3.8.10
・Intel CPU
必要なものをインストール
whisperをインストール
以下のコマンドでwhisperをインストールする。
pip install git+https://github.com/openai/whisper.git
依存関係のffmpegをインストールする。
(無くても動く場合もある)
pip install ffmpeg-python
Speech Recognitionをインストール
pip install SpeechRecognition
依存関係のPyAudioをインストールする。
sudo apt install python3-pyaudio
その他必要なものをインストール
SoundFile
pip install soundfile
numpy
pip install numpy
ソースコード
from io import BytesIO
import numpy as np
import soundfile as sf
import speech_recognition as sr
import whisper
if __name__ == "__main__":
model = whisper.load_model("medium")
recognizer = sr.Recognizer()
while True:
# マイクから音声を取得
with sr.Microphone(sample_rate=16_000) as source:
print("なにか話してください")
audio = recognizer.listen(source)
print("音声処理中 ...")
# 音声データをWhisperの入力形式に変換
wav_bytes = audio.get_wav_data()
wav_stream = BytesIO(wav_bytes)
audio_array, sampling_rate = sf.read(wav_stream)
audio_fp32 = audio_array.astype(np.float32)
result = model.transcribe(audio_fp32, fp16=False)
print(result["text"])
whisperのモデルは、mediumが良さそうです。
whisperの出力はJSON形式であり、今回必要なものは認識した文字列です。
result["text"]と書くことで、認識した文字列だけを抽出することができます。
miibo(旧mebo)をPythonで使ってみた
最近GPT-3などが出てきて、AIと簡単に会話できるようになりました。
そこで、私もAIと会話したいと思ったので、いろいろ調べてみました。
調べていく中で、meboと言った会話型AI構築サービスが面白そうだったので、触ってみました。
(キャラ設定ができるので、他のAIと差別化できそう)
ここでは、Pythonで作成したエージェントとAPI経由で会話する方法を書いています。
・meboの公式サイト
・使い方は、開発者さんのZennに詳しく書いています。
meboでAPIを共有する方法は、以下の記事を見てください。
作成したエージェントとAPI経由で会話する|miibo(ミーボ)ではじめる会話AI構築
必要なもの
mebo側
・エンドポイント
・APIキー
・エージェントID
・ユーザの発話
・ユーザ識別子
・エンドポイント(共通)
https://api-mebo.dev/api
APIキー、エージェントIDは、以下の場所から入手できます。
ユーザ識別子(uid)を含めると、ユーザごとにステートを保持することができるので、必要な人は任意のユーザー識別子を設定してください。
Python側
meboとのやり取りは、Pythonで使われるHTTPライブラリであるrequestsを使用しました。
以下のコマンドでインストールしてください。
pip install requests
ソースコード
テストコードは以下の通りです。
import requests
url = "https://api-mebo.dev/api"
headers = {'content-type': 'application/json'}
item_data = {
"api_key": "APIキー",
"agent_id": "エージェントID",
"utterance": "今日の天気は",
"uid": "ユーザ識別子"
}
r = requests.post(url,json=item_data,headers=headers)
print(r)
print(r.json()["utterance"])
print(r.json()["bestResponse"]["utterance"])
解説
urlにエンドポイント
headersにリクエストヘッダー
item_dataにリクエストパラメータ
utteranceに会話内容(今回は「今日の天気は」と質問する)
r = requests.post(url,json=item_data,headers=headers)で、rにレスポンスデータを格納する。
レスポンスはJson形式です。
print(r)でステータスコードを表示します。
print(r.json())で、レスポンス内容を表示できます。
以下は、Zennに記載されているレスポンスの例です。
{
"utterance": "おはようございます!",
"bestResponse": {
"utterance": "おはようございます!!良い天気ですね。",
"options": [
"他の話題",
"調子はどう?",
"今日は何して過ごそう"
],
"topic": "",
"imageUrl": "",
"url": "",
"isAutoResponse": false,
"extensions": {
"key1": "value1",
"key2": "value2"
}
}
}
しかし、欲しいものは、"utterance": "おはようございます!"と"utterance": "おはようございます!!良い天気ですね。"なので、以下のようにして欲しいものを取り出す。
自分がした会話は、"utterance"なので、
print(r.json()["utterance"])
返答は、"bestResponse"の中にある"utterance"なので、
print(r.json()["bestResponse"]["utterance"])
とすれば以下のように欲しいものが取り出せます。

連続して会話するコード
テストコードでは1回限りの会話でしたので、最後に連続して会話できるコードを書いておきます。
import requests
# meboAPIの使用
def mebo(text):
url = "https://api-mebo.dev/api"
headers = {'content-type': 'application/json'}
item_data = {
"api_key": "APIキー",
"agent_id": "エージェントID",
"utterance": text,
"uid": "ユーザ識別子"
}
r = requests.post(url,json=item_data,headers=headers)
return r
if __name__ == "__main__":
while True:
# mebo雑談
text = input("会話内容を入力してください")
r = mebo(result["text"])
print(r)
print(r.json()["bestResponse"]["utterance"])
Ubuntu20.04にアップグレードした話
今までLinuxOSである『voyager』といったOSを使用していました。(研究室のPCが全てそれだったから)しかし、『voyager』が使いにくいとかいった理由(個人差あり)からUbuntuに乗り換えることにした。なので、乗り換え方法を書いておこうと思います。
この記事は、既にUbuntuをインストールしている人向けです。
やり方
①必要なデータをバックアップする。(初期化されるので、データは全て消えます。)
②インストールメディアを作る。
以降の手順はUbuntuを初めてインストールする方法とほぼ同じです。
以下のサイトを参考にして下さい。(パーテーションの分割はやらなくて大丈夫です。)
インストールメディアを起動して、上記のサイトの『インストールの種類』まで進めて下さい。
③『インストールの種類』で『それ以外』を選択する。
④Ubuntuが入っているディスクを選択します。(既にUbuntuが入って入れは、『システム』にUbuntuの記載があります。)
⑤『パーテーションの編集』から、
・利用方法:ext4ジャーナリングファイルシステム
・パーテーションの初期化にチェックを入れる
・マウントポイントを『/』
にして、『OK』ボタンを押す。
⑥『ブートローダをインストールするデバイス』を⑤で初期化したディスクを選択する。
⑦最終確認をして『インストール』ボタンを押す。
⑧以降は新しくUbuntuをインストールする方法と同じです。
注意
・アップデートは自己責任でお願いします。
・各作業しっかりと確認して下さい。
MATLABでモータの効率マップを作る
モータの研究をやっている人からMATLABでモータの効率マップの作り方を聞かれたのでその作り方をここに書いておこうと思う。
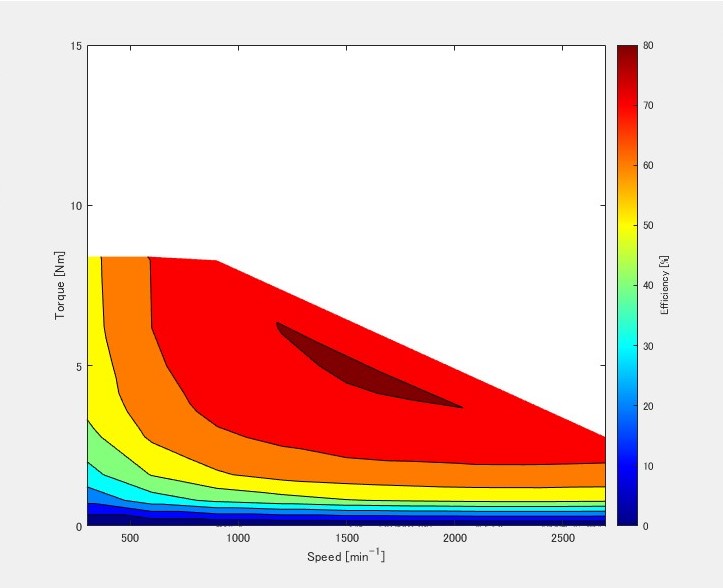 ↑こんな感じのグラフをつくる
↑こんな感じのグラフをつくる
環境
MATLAB R2020A
作り方
先ず、Excelなどで取得したデータをcsvファイルに変換する。 今回は以下のようなデータで効率マップを作る。 A列がスピード、B列がトルク、C列が効率のデータになっている。
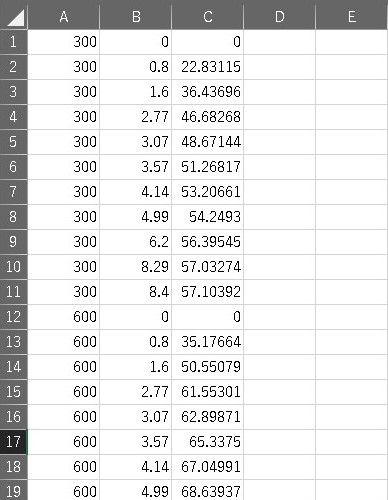
MATLABを開き、新規スクリプトを作成し、csvファイルがあるディレクトリに保存する。 そして以下のコードを記述する。
%モータの効率マップの作成
%データの読み込み
a = load('{ファイルの名前}.csv');
%各行のデータを格納
speed = a(:,1);
torque = a(:,2);
efficiency = a(:,3);
%等高線図用のデータの作成
x0 = min(speed) ; x1 = max(speed) ; nx = 1000 ;
y0 = min(torque) ; y1 = max(torque) ; ny = 1000 ;
x = linspace(x0,x1,nx) ;
y = linspace(y0,y1,ny) ;
[X,Y] = meshgrid(x,y) ;
Z = griddata(speed,torque,efficiency,X,Y);
%塗りつぶした 2 次元等高線図の作成
contourf(X,Y,Z);
%contourf(X,Y,Z,'LineStyle','none');
%軸の範囲指定
axis([300,2700,0,15])
%X軸ラベル
xlabel('Speed [min^-^1]')
%Y軸ラベル
ylabel('Torque [Nm]')
%カラーバーのラベル
c = colorbar;
c.Label.String = 'Efficiency [%]';
%色の変更
colormap(jet);
%colormapeditor;%colormapの編集
記入後、実行すると以下のようなグラフができる。
注意
- ファイルの名前は英語で先頭を数字にしない
- 読み込むデータの名前を自分のものに変更する