Pythonを使ってAIとおしゃべりがしたい
AIの友達が欲しい。
AIとおしゃべりがしたい。
去年からそんなことを思いつつ、色々試していました。
そして最近、便利なツールがたくさん出てきたおかげで、AIとおしゃべりできるシステムが簡単に作れるようになりました。
そこで、私なりに作ってみた(組み合わせただけ)会話システムをまとめました。
この記事でできること
AIとおしゃべり(雑談)するシステムをPythonで作ることができます。
具体的には、マイク入力、音声認識、雑談生成、感情認識、音声合成です。
使ったもの
・whisper(音声認識)
・mebo(雑談)
・Cotoha API(感情認識)
・VOICEVOX(音声合成)
目次
今まで作ったもの
初めて会話システムを作ったときに利用したのが、名古屋工業大学が開発したMMDAgentです。
MMDAgentは、決められた通りの受け答えしかできません。
そして、だいぶ前に開発されたものなので、外部との連携ができませんでした。
そのため、友達1号の開発は終了しました。
 続いて、ドコモAIエージェントサービスを使用して、AIと会話するシステムを作りました。
続いて、ドコモAIエージェントサービスを使用して、AIと会話するシステムを作りました。
システムの構成は下の図の通りです。
 GUIには、Unityを使用しており、音声認識や音声合成、シナリオ作成にはドコモAIエージェントサービスを使用しています。そして、雑談や天気予報などは外部のAPIを使用していました。
GUIには、Unityを使用しており、音声認識や音声合成、シナリオ作成にはドコモAIエージェントサービスを使用しています。そして、雑談や天気予報などは外部のAPIを使用していました。
しかし、雑談をするために会話型AI構築サービスのmeboをドコモAIエージェントと連携させようとしましたが、できませんでした。
そのため雑談には、chaplus 対話API βを使用していたが、それも最近サービスが終了してしまいました。
そして、友達2号の開発は終了しました。
今回作ったもの
ドコモAIエージェントサービスもいつまで使えるか分からないので、ドコモAIエージェントサービスの部分をPythonで作りました。
開発環境
・Ubuntu20.04
・Intel core i7 7700hq
・GeForce GTX1050
構成
全体の流れは、以下の通りです。
ユーザーの発話
↓
whisper(音声認識)
↓
mebo(返事を生成)
↓
Cotoha API(返事の感情を認識)
↓
VOICEVOX(音声合成)
↓
ユーザー
whisper
whisperは、OpenAIが公開したオープンソースの素晴らしい音声認識モデルです。
これを使用することにより、ローカル環境で高精度な音声認識を行えます。
mebo
meboは、GPTベースの会話型AI構築サービスです。
キャラクターも設定できて面白いです。
Cotoha API
NTTグループの40年以上の研究成果を活かした自然言語処理技術や音声認識・合成技術を、APIでお手軽に利用できるよう提供しているサービスです。
VOICEVOX
無料で使える中品質なテキスト読み上げソフトウェアです。
インストール
音声認識
whisperをインストール
以下のコマンドでwhisperをインストールする。
pip install git+https://github.com/openai/whisper.git
依存関係のffmpegをインストールする。
(無くても動く場合もある)
pip install ffmpeg-python
Speech Recognitionをインストール
pip install SpeechRecognition
依存関係のPyAudioをインストールする。
sudo apt install python3-pyaudio
その他必要なものをインストール
SoundFile
pip install soundfile
numpy
pip install numpy
返事を生成、返事の感情を認識
mebo、Cotoha APIとのやり取りには、Pythonで使われるHTTPライブラリであるrequestsを使用しました。
pip install requests
VOICEVOXをインストール
VOICEVOXは、以下のサイトを参考にしてインストールしてください。
GPU環境がない人は、CPU版をインストールしてください。
VOICEVOXで生成された音声ファイルを再生するためにplaysoundを使用しました。
pip install playsound
APIの準備
mebo
下のサイトからmeboを作って下さい。
meboの詳しい使い方は、下の記事を見てください。
meboでAPIを共有する方法は、下の記事を見てください。
作成したエージェントとAPI経由で会話する|mebo(ミーボ)ではじめる会話AI構築
必要なもの
・エンドポイント
・APIキー
・エージェントID
・ユーザの発話
・ユーザ識別子
エンドポイント(共通)
https://api-mebo.dev/api
APIキー、エージェントIDは、以下の場所から入手できます。

ユーザ識別子(uid)を含めると、ユーザごとにステートを保持することができるので、必要な人は任意のユーザー識別子を設定してください。
Cotoha API
下のサイトからCotoha APIのアカウントを作って下さい。
api.ce-cotoha.com
詳しい使い方は公式リファレンスを見てください。
必要なもの
・client_id
・client_secret
・Access Token Publish URL
Access Token Publish URL (共通)
https://api.ce-cotoha.com/v1/oauth/accesstokens
ソースコード(GPU)
###################################
# AIトークシステム
# VOICEVOXを起動させてから実行する
###################################
from io import BytesIO
import numpy as np
import soundfile as sf
import speech_recognition as sr
import whisper
import requests
import json
import wave
from pprint import pp
from playsound import playsound
# whisperでマイクから文字起こし
def transcription(model,recognizer):
with sr.Microphone(sample_rate=16_000) as source:
print("なにか話してください")
audio = recognizer.listen(source)
print("音声処理中 ...")
wav_bytes = audio.get_wav_data()
wav_stream = BytesIO(wav_bytes)
audio_array, sampling_rate = sf.read(wav_stream)
audio_fp32 = audio_array.astype(np.float32)
result = model.transcribe(audio_fp32, fp16=False,language="ja")
print(result["text"])
return result
# VOICEVOXで音声合成
def generate_wav(text, speaker=8, filepath='./audio.wav'):
host = 'localhost'
port = 50021
params = (
('text', text),
('speaker', speaker),
)
response1 = requests.post(
f'http://{host}:{port}/audio_query',
params=params
)
headers = {'Content-Type': 'application/json',}
response2 = requests.post(
f'http://{host}:{port}/synthesis',
headers=headers,
params=params,
data=json.dumps(response1.json())
)
wf = wave.open(filepath, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(24000)
wf.writeframes(response2.content)
wf.close()
# meboAPIの使用
def mebo(text):
url = "https://api-mebo.dev/api"
headers = {'content-type': 'application/json'}
item_data = {
"api_key": "APIキー",
"agent_id": "エージェントID",
"utterance": text,
"uid": "ユーザ識別子"
}
r = requests.post(url,json=item_data,headers=headers)
print(r)
print(r.json()["bestResponse"]["utterance"])
return r
# cotohaAPIの使用
def cotoha(sentence):
client_id = 'Client ID って書いてあるところにあるやつ'
client_secret = 'Client Secret って書いてあるところにあるやつ'
url = 'Access Token Publish URL って書いてあるところにあるやつ'
headers = {
'Content-Type': 'application/json'
}
data = json.dumps({
'grantType' : 'client_credentials',
'clientId' : client_id,
'clientSecret': client_secret
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
access_token = response['access_token']
# 解析モード選択(今回は感情認識)
url = 'https://api.ce-cotoha.com/api/dev/nlp/v1/sentiment'
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'Authorization': f'Bearer {access_token}'
}
data = json.dumps({
'sentence': sentence
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
# 辞書を見やすく整形して出力
pp(response)
# return response
if __name__ == "__main__":
# wisperの設定
model = whisper.load_model("base",device="cpu")
_ = model.half()
_ = model.cuda()
for m in model.modules():
if isinstance(m, whisper.model.LayerNorm):
m.float()
recognizer = sr.Recognizer()
while True:
# whisperマイクから文字起こし
result = transcription(model,recognizer)
# mebo雑談
r = mebo(result["text"])
# cotoha感情認識
cotoha(r.json()["bestResponse"]["utterance"])
# 音声合成
generate_wav(r.json()["bestResponse"]["utterance"])
# 音声再生
playsound("audio.wav")
実行させる前に、VOICEVOX(GUI)を起動させておく。
ソースコード(CPU)
###################################
# AIトークシステム
# VOICEVOXを起動させてから実行する
###################################
from io import BytesIO
import numpy as np
import soundfile as sf
import speech_recognition as sr
import whisper
import requests
import json
import wave
from pprint import pp
from playsound import playsound
# whisperでマイクから文字起こし
def transcription(model,recognizer):
with sr.Microphone(sample_rate=16_000) as source:
print("なにか話してください")
audio = recognizer.listen(source)
print("音声処理中 ...")
wav_bytes = audio.get_wav_data()
wav_stream = BytesIO(wav_bytes)
audio_array, sampling_rate = sf.read(wav_stream)
audio_fp32 = audio_array.astype(np.float32)
result = model.transcribe(audio_fp32, fp16=False,language="ja")
print(result["text"])
return result
# VOICEVOXで音声合成
def generate_wav(text, speaker=8, filepath='./audio.wav'):
host = 'localhost'
port = 50021
params = (
('text', text),
('speaker', speaker),
)
response1 = requests.post(
f'http://{host}:{port}/audio_query',
params=params
)
headers = {'Content-Type': 'application/json',}
response2 = requests.post(
f'http://{host}:{port}/synthesis',
headers=headers,
params=params,
data=json.dumps(response1.json())
)
wf = wave.open(filepath, 'wb')
wf.setnchannels(1)
wf.setsampwidth(2)
wf.setframerate(24000)
wf.writeframes(response2.content)
wf.close()
# meboAPIの使用
def mebo(text):
url = "https://api-mebo.dev/api"
headers = {'content-type': 'application/json'}
item_data = {
"api_key": "APIキー",
"agent_id": "エージェントID",
"utterance": text,
"uid": "ユーザ識別子"
}
r = requests.post(url,json=item_data,headers=headers)
print(r)
print(r.json()["bestResponse"]["utterance"])
return r
# cotohaAPIの使用
def cotoha(sentence):
client_id = 'Client ID って書いてあるところにあるやつ'
client_secret = 'Client Secret って書いてあるところにあるやつ'
url = 'Access Token Publish URL って書いてあるところにあるやつ'
headers = {
'Content-Type': 'application/json'
}
data = json.dumps({
'grantType' : 'client_credentials',
'clientId' : client_id,
'clientSecret': client_secret
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
access_token = response['access_token']
# 解析モード選択(今回は感情認識)
url = 'https://api.ce-cotoha.com/api/dev/nlp/v1/sentiment'
headers = {
'Content-Type': 'application/json;charset=UTF-8',
'Authorization': f'Bearer {access_token}'
}
data = json.dumps({
'sentence': sentence
})
with requests.post(url, headers=headers, data=data) as req:
response = req.json()
# 辞書を見やすく整形して出力
pp(response)
# return response
if __name__ == "__main__":
# wisperの設定
model = whisper.load_model("base",device="cpu")
recognizer = sr.Recognizer()
while True:
# whisperマイクから文字起こし
result = transcription(model,recognizer)
# mebo雑談
r = mebo(result["text"])
# cotoha感情認識
cotoha(r.json()["bestResponse"]["utterance"])
# 音声合成
generate_wav(r.json()["bestResponse"]["utterance"])
# 音声再生
playsound("audio.wav")
実行させる前に、VOICEVOX(GUI)を起動させておく。
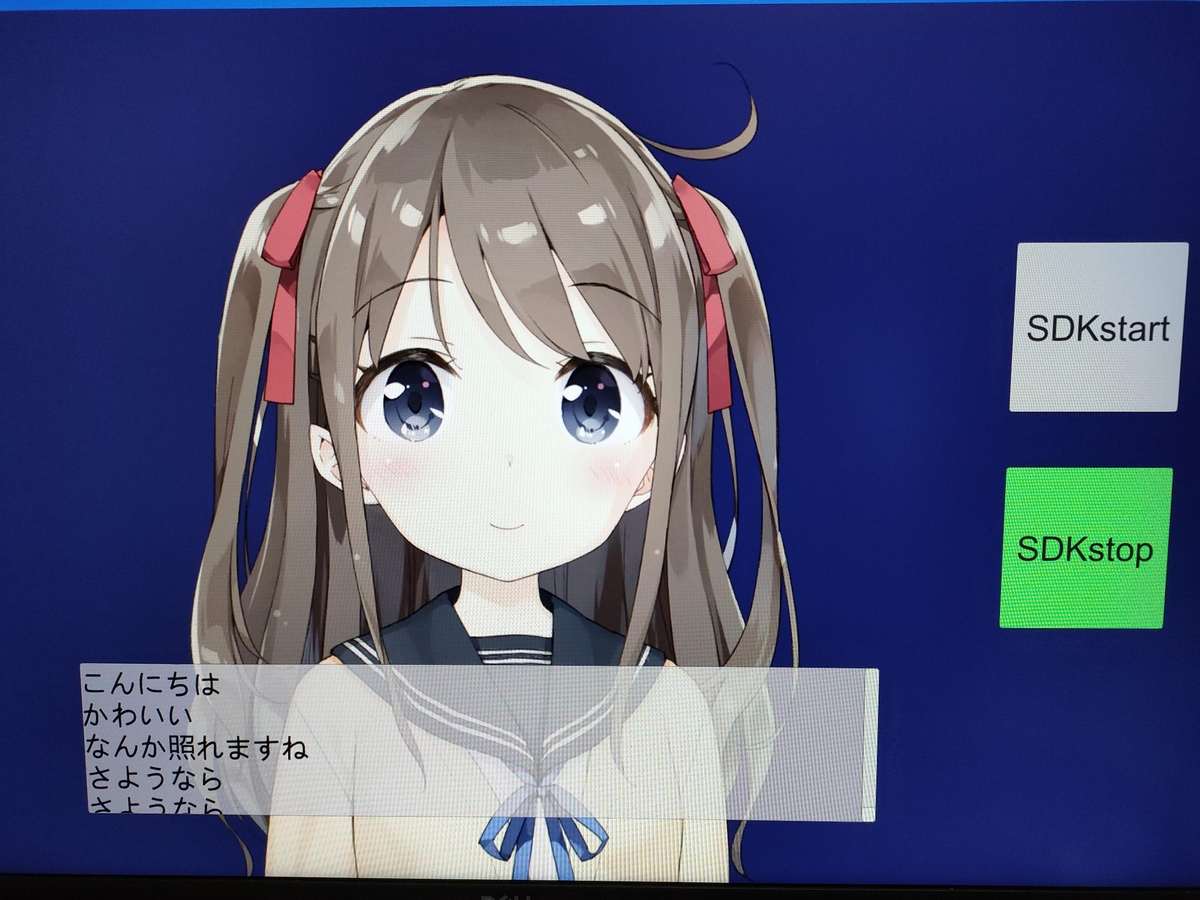
実行結果
結果は下の図のようになります。

「こんにちは」と話しかけると、「こんにちは!」と返してくれました。
また、resultに感情の結果も出力されています。今回は、sentimentがNeutralで、そのスコアが、0.4826886679492818となりました。
この感情表現の結果をもとに、キャラクターの表情やしゃべり方を変えると、いい感じに会話できると思います。
ソースコードの説明
whisperでマイクから文字起こし
以前に書いた記事を見てください。
whisperのモデルは5種類用意されています。
ここではbaseを使用しています。
感激!✨こんなに少ないコードで音声を文字に変換できるなんて😭✨感激し過ぎたせいで全モデル試してしもた!! pic.twitter.com/WPY337P1Qx
— みやさかしんや@Python/DX/エンジニア (@miyashin_prg) February 10, 2023
mebodで雑談の返答を生成
以前に書いた記事を見てください。
Cotoha APIで感情認識
下の記事を参考にしました。
VOICEVOXで音声合成
下の記事を参考にしました。
def generate_wav(text, speaker=8, filepath='./audio.wav'):のspeaker=の数字を変えることで、読んでくれるキャラクターが変わります。
話者ID一覧
0 四国めたん あまあま
1 ずんだもん あまあま
2 四国めたん 四国めたん
3 ずんだもん ずんだもん
4 四国めたん セクシー
5 ずんだもん セクシー
6 四国めたん ツンツン
7 ずんだもん ツンツン
8 春日部つむぎ 春日部つむぎ
9 波音リツ 波音リツ
10 雨晴はう 雨晴はう
11 玄野武宏 玄野武宏
12 白上虎太郎 ふつう
13 青山龍星 青山龍星
14 冥鳴ひまり 冥鳴ひまり
15 九州そら あまあま
16 九州そら 九州そら
17 九州そら セクシー
18 九州そら ツンツン
19 九州そら ささやき
20 もち子さん もち子さん
21 剣崎雌雄 剣崎雌雄
22 ずんだもん ささやき
23 WhiteCUL WhiteCUL
24 WhiteCUL たのしい
25 WhiteCUL かなしい
26 WhiteCUL びえーん
27 後鬼 人間ver.
28 後鬼 ぬいぐるみver.
29 No.7 No.7
30 No.7 アナウンス
31 No.7 読み聞かせ
32 白上虎太郎 わーい
33 白上虎太郎 びくびく
34 白上虎太郎 おこ
35 白上虎太郎 びえーん
36 四国めたん ささやき
37 四国めたん ヒソヒソ
38 ずんだもん ヒソヒソ
whiperの高速化(ちょっとだけ)
下の記事を参考にしましました。
今回は記事に書いてある、重みのfp16化を行いました。
Whisper自体の変更は無く、呼び出し方を変え、重みも fp16 で演算することによって若干の高速化と省メモリ化を行います。
import whisper
model = whisper.load_model("base", device="cpu")
_ = model.half()
_ = model.cuda()
# exception without following code
# reason : model.py -> line 31 -> super().forward(x.float()).type(x.dtype)
for m in model.modules():
if isinstance(m, whisper.model.LayerNorm):
m.float()
今後の課題
今後は、GUIを作って、キャラクターにしゃべってもらいたいです。
また、雑談の返答と感情認識以外はローカルで動かいているので、その2つもローカルで動くようにさせたいです。
参考サイト
・whisperを使ってマイクから文字起こしをする部分
声をPythonに聴かせて(マイクから入力した声をWhisperに、何度でも認識させよう) - nikkie-ftnextの日記
・mebo公式リファレンス
mebo(ミーボ)ではじめる会話AI構築
・PythonとAPIのやり取りをしている部分
Python, RequestsでWeb APIを呼び出し(データ取得・操作) | note.nkmk.me
・Cotoha API公式リファレンス
APIリファレンス | COTOHA API
・Cotoha APIとPythonの連携
Cotoha API を使ってみた | Withcation
・VOICEVOXとPythonの連携
PythonからVOICEVOXを使う - Qiita
VOICEVOXエンジンを使ったPythonでの「高」品質音声合成API | 鷹の目週末プログラマー
・whisperの高速化の部分
音声認識モデル Whisper の推論をほぼ倍速に高速化した話 - Qiita